
Pretrained Language Models for Text Generation: A Survey 论文翻译
原论文:Pretrained Language Models for Text Generation: A Survey
摘要
文本生成已成为自然语言处理 (NLP) 中最重要但最具挑战性的任务之一。 深度学习的复兴通过神经生成模型,尤其是预训练语言模型 (PLM) 的范式,极大地推动了这一领域的发展。 在本文中,我们概述了在用于文本生成的 PLM 主题中取得的主要进展。 作为准备工作,我们介绍了一般任务定义并简要描述了用于文本生成的 PLM 的主流架构。 作为核心内容,我们讨论了如何调整现有的 PLM 以对不同的输入数据进行建模并满足生成文本的特殊属性。 我们进一步总结了几个重要的文本生成微调策略。 最后,我们提出了几个未来的方向并总结了本文。 我们的调查旨在为文本生成研究人员提供相关研究的综合和指针。
1 、简介
文本生成,通常被正式称为自然语言生成,已成为自然语言处理 (NLP) 中最重要但最具挑战性的任务之一。 它旨在从输入数据(例如,序列和关键字)中以人类语言生成合理且可读的文本。 研究人员已经为文本生成的广泛应用开发了多种技术 [Li et al., 2021a]。 例如,机器翻译根据源文本生成不同语言的文本 [Yang et al., 2020a]; 摘要生成源文本的删节版本以包含显着信息 [Guan et al., 2020]。
随着最近深度学习的复苏,人们提出了各种工作来解决基于循环神经网络 (RNN) [Li et al., 2019]、卷积神经网络 (CNN) [Gehring et al., 2017] 的文本生成任务, 图神经网络 (GNN) [Li et al., 2020] 和注意力机制 [Bahdanau et al., 2015]。 这些神经模型的优点之一是它们能够在文本生成中对从输入到输出的语义映射进行端到端学习。 此外,神经模型能够学习低维、密集的向量来隐式表示文本的语言特征,这也有助于缓解数据稀疏性。
尽管用于文本生成的神经模型取得了成功,但主要的性能瓶颈在于大规模数据集的可用性。 大多数监督文本生成任务的现有数据集都相当小(机器翻译除外)。 深度神经网络通常需要学习大量参数,这些参数很可能在这些小数据集上过拟合,并且在实践中不能很好地泛化。
近年来,预训练语言模型 (PLM) 的范式正在蓬勃发展 [Peters et al., 2018]。这个想法是首先在大规模语料库中预训练模型,然后在各种下游任务中微调这些模型以实现最先进的结果。人们普遍认为,PLM 可以从语料库中编码大量语言知识并诱导语言的通用表示。因此,PLM 通常有利于下游任务,并且可以避免从头开始训练新模型 [Brown et al., 2020]。此外,随着计算能力的提高和 Transformer 架构的出现 [Vaswani et al., 2017],PLMs 从浅到深发展,并在许多任务中取得了出色的性能,例如 BERT [Devlin et al., 2019] 和GPT [Radford et al., 2019]。因此,研究人员提出了各种方法来解决基于 PLM 的文本生成任务。在大规模语料库上进行预训练,PLM 能够准确理解自然语言并流利地用人类语言表达,这两者都是完成文本生成任务的关键能力。该领域的现有调查仅部分审查了一些相关主题。 Zaib et al. [2020]和 Guan et al. [2020] 提供了对一些文本生成子任务(即对话系统和摘要)的研究的综合,但没有更广泛地扩展到其他重要的生成任务。邱等人。 [2020] 总结了整个 NLP 领域的两代 PLM,并介绍了 PLM 的各种扩展和适应方法。据我们所知,我们的调查是第一项全面审查用于文本生成的 PLM 的工作。它旨在为文本生成研究人员提供相关研究的综合和指针。
首先,我们首先在第 2 节中提出一个通用的任务定义,其中包含不同文本生成任务的公式,然后在第 3 节中简要描述用于文本生成的 PLM 的主流架构。由于文本生成的核心 是对从输入到输出的语义映射进行建模,我们在第 4-5 节中进一步组织了关于输入和输出两个方面的主要进展。 对于输入,我们主要讨论如何使现有 PLM 适应不同的数据类型。 对于输出,我们研究如何满足生成文本的特殊属性。 此外,我们在第 6 节总结了几个重要的文本生成微调策略。最后,我们提出了几个未来的方向,并在第 7 节总结了本文。
2 、任务和典型应用
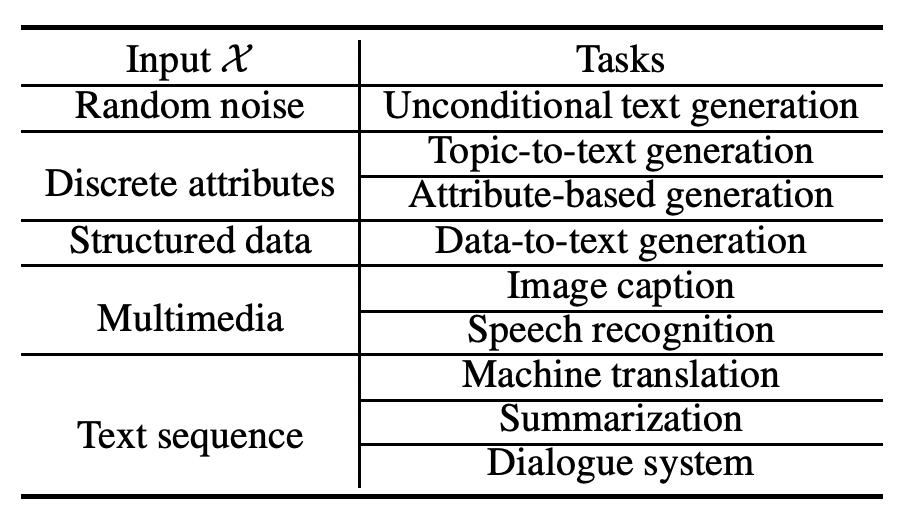
接下来,我们正式定义文本生成任务。 文本生成的核心是生成一系列离散标记 Y = (),其中每个 都是从一个单词词汇表 中提取的。在大多数情况下,文本生成是以输入数据为条件的,例如属性、文本和结构化数据,记为 。形式上,文本生成任务可以描述为 作为:
根据输入,我们接下来介绍几个文本生成的典型应用:
- 如果未提供 或随机噪声向量,则此任务将退化为语言建模或无条件生成任务 [Radford et al., 2019],旨在生成不受任何约束的文本。
- 如果 是一组离散属性(例如,主题词、情感标签),则任务变为主题到文本生成或基于属性的生成 [Keskar et al., 2019]。 中的信息起到指导文本生成过程和控制生成文本模式的作用。
- 如果 是知识图或表格之类的结构化数据,则此任务将被视为 KG 到文本或表格到文本的生成,称为数据到文本的生成 [Li et al., 2021c]。 此任务旨在生成有关结构化数据的描述性文本。
- 如果 是图像和语音等多媒体输入,则任务变为图像标题 [Xia et al., 2020] 或语音识别 [Fan et al., 2019]。 图像说明的核心是生成对图像的描述,而语音识别使程序能够将人类语音处理成文本格式。
- 最常见的形式也是文本序列,存在机器翻译、摘要和对话系统等多种应用。 机器翻译 [Conneau and Lample, 2019] 旨在将文本从一种语言自动翻译成另一种语言,摘要 [Zhang et al., 2019b] 专注于生成长文档的简明摘要,以及对话系统 [Wolf et al., 2019]旨在使用自然语言与人类交谈。
我们在表 1 中展示了主要文本生成的公式。
3 、 文本生成的标准架构
预训练语言模型 (PLM) 使用大量未标记的文本数据进行预训练,并且可以在下游生成任务上进行微调。 PLM在大规模语料库上进行预训练,将海量的语言和世界知识编码成大量的参数,可以增强对语言的理解,提高生成质量。 预训练的想法是受到人类的启发,即我们转移和重用我们过去所学的旧知识来理解新知识并处理各种新任务。 通过这种方式,PLM 可以利用他们的旧经验和知识成功地执行新任务。
由于 Transformer [Vaswani et al., 2017] 取得的巨大成就,几乎所有 PLM 都采用了 Transformer 的主干。 对于文本生成任务,一些 PLM 使用遵循基本encoder-decoder的标准 Transformer 架构,而另一些则应用decoder-only Transformer。 接下来,我们将依次介绍这两种方法。
Encoder-decoder Transformer. 标准的 Transformer 使用encoder-decoder架构,它由两个 Transformer 块堆栈组成。 encoder被输入一个输入序列,而decoder旨在基于encoder-decoder self-attention机制生成输出序列。 基于上述架构,MASS [Song et al., 2019]、T5 [Raffel et al., 2020] 和 BART [Lewis et al., 2020] 等模型提高了生成文本的质量。
Decoder-only Transformer. GPT 等模型 [Radford et al., 2019; Brown et al., 2020] 和 CTRL [Keskar et al., 2019] 采用单个 Transformer decoder块,通常用于语言建模。 他们应用单向self-attention masking,即每个token只能关注先前的tokens。
除了语言建模之外,一些作品还利用decoder-only的结构来生成以输入文本为条件的文本。 但是,这些模型没有独立的模块来encode输入序列。 有趣的是,他们将输入和输出序列与一个特殊的标记(例如,“[SEP]”)连接起来,并使用一种新颖的 seq2seq masking [Dong et al., 2019],输入句子中的每个token都可以相互关注并生成tokens可以处理所有输入tokens和先前生成的tokens。 与单向masking相比,seq2seq masking是decoder-only PLM 解决条件生成任务的一种自然方式,类似于encoder-decoder架构。 [Raffel et al. 2020] 研究了上述两种方法之间的performance,并得出结论,添加 explicit encoder-decoder attention是有益的。
文本生成任务的核心是学习从输入到输出的语义映射。 一方面,不同的任务会对应多种输入数据,我们需要开发特殊的技术来对不同的数据类型进行建模。 另一方面,生成的文本应该满足重要的属性,以应对不同的任务要求。 接下来,我们讨论关于两个方面的最新进展,即输入和输出。
4 、从输入建模不同的数据类型
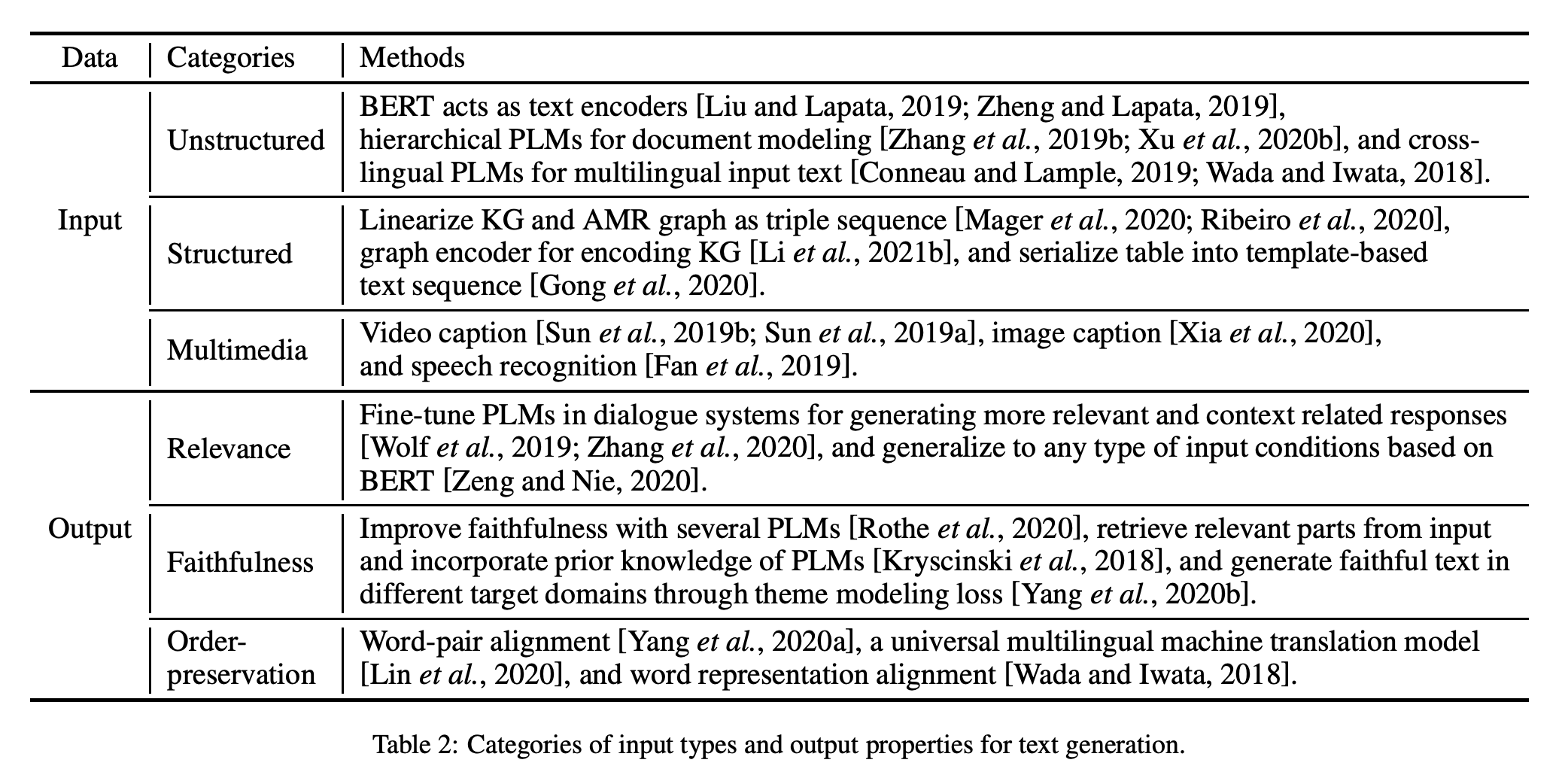
如第 2 节所述,不同的文本生成任务通常涉及特定类型的输入。 在本节中,我们将介绍用于文本生成的三种主要输入类型,即非结构化输入、结构化输入和多媒体输入,并讨论如何在 PLM 中对这些输入数据进行建模。
4.1 、非结构化输入
在 NLP 研究中,大多数研究都集中在对非结构化文本输入(例如句子、段落和文档)进行建模。 为了生成令人满意的输出文本,它需要超越输入文本中单个单词的表面含义的出色语言理解能力。 因此,Liu and Lapata [2019] 和 Zheng and Lapata [2019] 采用 PLM(例如,BERT [Devlin et al., 2019])作为文本编码器,用于将文本压缩为低维向量,同时保留其大部分含义。 与传统的浅层神经模型(例如 CNN)相比,PLM 具有大量参数,编码海量的世界知识,这可能有利于捕捉文本的核心含义。
在某些情况下,输入文本可能是由多个句子和段落组成的长文档。 对于在句子或短段落上训练的 PLM,它们在文档中准确建模长期依赖关系的能力较差。 考虑到这一挑战,Zhang et al. [2019b] 和Xu et al. [2020b] 提出了分层 BERT 来学习具有self-attention的句子之间的交互以进行文档 encoding。 此外,为了捕获句间关系,DiscoBERT [Xu et al., 2020a] 在 BERT 之上堆叠了图卷积网络 (GCN) 以对结构性话语图进行建模。 通过直接对话语单元进行操作,DiscoBERT 保留了包含更多概念或上下文的能力,从而产生更简洁和信息丰富的输出文本。
我们观察到最近的 PLM 都是在英文文本上进行预训练的。 同时,许多多语言生成任务(例如机器翻译)涉及多种语言,并且某些语言资源不足。 这一挑战阻碍了单语 PLM 在多语文本生成任务中的广泛应用。 因此,Conneau 和 Lample [2019] 提出学习跨语言语言模型 (XLM) 以进行多语言语言理解。 基于跨语言 PLM,文本生成模型即使在低资源语言中仍然可以获得有效的输入word embeddings [Wada and Iwata, 2018]。
4.2 、结构化输入
结构化数据(例如,图形和表格)也是许多现实世界应用程序(如天气报告生成)中文本生成的关键输入类型。 然而,在现实世界的场景中,很难收集大量带有真实文本的标记结构化数据进行训练。 由于在大规模语料库上进行了预训练,PLM 编码了大量的语言知识,并在许多任务中表现出出色的小样本能力。 受此启发,Chen et al. [2020b] 和Gong et al. [2020] 探索了将 PLM 用于数据到文本的生成,尤其是在少样本设置中。
将 PLM 应用于结构化数据时,一个主要挑战是如何将结构化数据输入 PLM,而 PLM 最初是为顺序文本设计的。为了适应 PLM 的顺序性,Ribeiro et al. [2020] and Mager et al. [2020]将输入知识图 (KG) 和抽象意义表示 (AMR) 图线性化为三元组序列,Li et al. [2021b] 引入了一个额外的图形编码器来对输入 KG 进行编码,Gong et al. [2020] 采用基于模板的方法将输入表序列化为文本序列。例如,属性值对“name: jack reynolds”将被序列化为句子“name is jack reynolds”。但是,直接线性化会丢失原始数据的结构信息,这可能导致生成关于数据的不忠实文本。因此,除了生成忠实的文本外,Gong et al. [2020] 提出了一种辅助重建任务,用于恢复输入数据的结构信息,可以增强对结构信息的建模能力。
通常,输出文本应尽可能多地保留结构化数据中的重要信息。 因此,为了生成符合输入的高保真文本,采用指针生成器机制 [See et al., 2017] 从输入的知识数据中复制单词 [Chen et al., 2020b]。 通过将 PLM 建立在外部知识上,它很可能赋予生成模型既丰富的知识又具有良好的泛化能力。 此外,Gong et al. [2020] p提出了一种内容匹配损失,用于测量输入数据中的信息与输出文本之间的距离。
4.3 、多媒体输入
除了上述文本数据之外,还进行了一些尝试以将图像字幕和语音识别等多媒体数据(例如,图像、视频和语音)作为输入。 VideoBERT [Sun et al., 2019b] 和 CBT [Sun et al., 2019a] 都对视频字幕任务进行了预训练。同时,他们仅对基于 BERT 的encoder进行预训练,以学习视觉和语言tokens序列上的双向联合分布。所以他们必须训练一个单独的视频到文本decoder,这往往会导致pretrain-finetune差异。相比之下,Unified VLP [Zhou et al., 2020] 使用共享的多层 Transformer 网络进行编码和解码。在 UniLM [Dong et al., 2019] 之后,他们在两个掩码语言建模 (MLM) 任务上对模型进行了预训练,例如为sequence-to-sequence LM 设计的完形填空任务。受到 GPT 中生成预训练目标的启发,Xia 等人。 [2020] 通过将图像作为输入并在预训练阶段使用图像字幕任务作为基本生成任务,提出了一种跨模态预训练模型 (XGPT)。
除了图像和视频之外,语音识别还需要人工转录的监督数据。 因此,开发了许多无监督和半监督方法来集成 PLM 以进行弱监督学习。 例如,Fan et al. [2019] 提出了一种无监督方法,用不成对的语音和转录本预训练encoder-decoder模型。 两个预训练阶段用于提取带有语音和转录本的声学和语言信息,这对于下游语音识别任务很有用。
5 、满足输出文本的特殊属性
在不同的文本生成任务中,生成的文本应该满足几个关键属性。 在本节中,我们将介绍文本生成中的三个关键属性,即相关性、忠实性和顺序保留。
Relevance. 根据语言学文献[Li et al., 2021c],在文本生成中,相关性是指输出文本中的主题与输入文本高度相关。 一个有代表性的例子是对话系统的任务,它要求生成的响应与输入对话历史相关。 除了对话历史之外,还可以提供对应于响应类型的条件作为外部输入,例如响应主题和说话者的角色。 生成的响应也应该与条件相关。 最近,由于缺乏长时记忆,基于 RNN 的模型仍然倾向于生成不相关的输出文本,并且与输入缺乏一致性。 因此,通过将 PLM 应用于对话系统的任务,TransferTransfo [Wolf et al., 2019] 和 DialoGPT [Zhang et al., 2020] 能够生成比传统的基于 RNN 的模型更相关和上下文一致的响应。
此外,为了推广到各种类型的条件,Zeng and Nie [2020] 利用详细的条件块来合并外部条件。 他们将 BERT 用于编码器和解码器,利用不同的输入表示和self-attention masks来区分对话的源端和目标端。 在目标(生成)端,采用了一种新的注意力路由机制来生成上下文相关的单词。 类似的方法已用于无条件对话 [Bao et al., 2020]。
Faithfulness. 同样,忠实度也是文本的一个关键属性,这意味着生成的文本中的内容不应与输入文本中的事实相矛盾。 有时,它进一步意味着生成的文本符合世界事实。 一个有代表性的例子是文本摘要的任务,其目的是生成忠实的文本,代表原始内容中最重要的信息。 PLM 对大量文本进行了预训练,可能有助于利用背景知识生成忠实的文本。 Rothe et al. [2020] 尝试了大量设置,以使用三个出色的 PLM(即 BERT、GPT 和 RoBERTa)初始化编码器和解码器。 通过预训练,模型更了解领域特征,更不容易出现语言模型漏洞。 因此,他们更有信心从文档中预测tokens,从而提高忠诚度。
为了提高摘要的忠实程度,Kryscinski et al. [2018] 提出将解码器分解为一个上下文网络,该网络检索源文档的相关部分,以及一个包含有关语言生成的先验知识的 PLM。 此外,为了在不同的目标域中生成忠实的文本,Yang et al. [2020b] 通过主题建模损失微调目标域上的 PLM。 主题建模模块的作用是使生成的摘要在语义上接近原文。
Order-preservation. 在 NLP 领域,order-preservation表示输入和输出文本中语义单元(单词、短语等)的顺序是一致的。最具代表性的例子是机器翻译的任务。在从源语言翻译到目标语言时,保持源语言和目标语言中短语的顺序一致,将在一定程度上保证翻译结果的准确性。实现order-preservation属性的一项研究是在机器翻译中执行语义对齐。 Yang et al. [2020a]了用于机器翻译的代码转换预训练 (CSP)。他们从源语言和目标语言中提取词对对齐信息,然后应用提取的对齐信息来增强顺序保留。此外,跨多种语言进行翻译更为常见,称为多语言机器翻译 [Conneau and Lample, 2019]。然而,很少有工作可以有效地增强任何语言对的order-preservation。因此,Lin et al. [2020] 提出了 mRASP,这是一种预训练通用多语言机器翻译模型的方法。 mRASP 的关键是随机对齐替换技术,它强制跨多种语言具有相似含义的单词和短语在表示空间中对齐。此外,Wada and Iwata [2018] 专注于对齐每种语言的词表示,从而可以保持跨多种语言的词序一致。
6 、文本生成的Fine-tuning策略
对于使用 PLM 生成文本,一个关键因素是如何设计合适的fine-tuning策略。 在这一部分中,我们从不同的角度回顾了几种常用的fine-tuning策略。
6.1 、Data View
在将 PLM 应用于文本生成任务时,尤其是在新领域中,如何设计适合新领域特征的合适且有效的微调策略是一个重要的考虑因素。
**Few-shot Learning.**在许多文本生成中,获得足够的annotated数据既困难又昂贵。 由于预训练的成功,PLMs 可以编码大量的语言和世界知识,这为数据稀缺性提供了有效的解决方案。 一种常用的方法是使用预训练参数插入现有模块。 然后我们针对所研究的任务用几个、一个甚至没有的例子来微调它,分别是所谓的few-shot、one-shot和zero-shot。
例如在多语言翻译中,一些低资源语言缺乏足够的并行语料库。 XLM [Conneau and Lample, 2019] 提出学习跨语言语言模型,并可以将在高资源语言中学到的知识用于低资源语言。 使用第 4 节中提出的方法,few-shot learning 也可以应用于数据到文本的任务,例如表格到文本的生成[Chen et al., 2020b; Gong et al., 2020] 和 KG-to-text generation[Li et al., 2021b]。 Chen et al. [2020b]直接为 GPT-2 提供少量序列化的属性值对和 Gong et al. [2020] 进一步应用了多个任务来更好地利用表格的结构化信息。 此外,Li et al. [2021b] 提出了表示对齐以弥合 KG 编码和 PLM 之间的语义差距,以增强 KG 和文本之间的对应关系。
Domain Transfer. PLM 配备大量参数并在大规模语料库上进行预训练,具有强大的泛化能力。 然而,它们仍然无法直接适应与预训练domain分布差异较大的新domains [Hendrycks et al., 2020]。 一个有效的解决方案是在对目标任务进行微调之前,继续使用具有预训练目标的特定数据训练 PLM。 Mask预测是一种广泛使用的方法,它试图使用剩余的tokens来预测被mask的tokens。 domain transfer中存在多种掩蔽方式。 Zeng and Nie [2020] 提出了基于 TF-IDF 的掩码,以选择更多与条件相关的tokens进行mask,以专注于domain特征。 文档masking通常用于摘要任务中,以捕获长文档的文档级特征 [Zhang et al., 2019b]。
6.2 、Task View
除了新domains的特征外,在微调 PLM 时考虑特定生成任务中的语言连贯性和文本保真度等一些特殊问题也很有意义。
Enhancing Coherence. 为了增强语言连贯性,一个重要的方法是在微调期间更好地建模语言上下文。 通过对比学习微调的模型擅长区分句子对是否相似。 通过这种方法,PLMs 被迫理解两个句子之间的位置或语义关系,以便它们能够得到更好的表示。
Next sentence prediction (NSP) 是一种常用的判断两个输入句子是否为连续句段的方法,可应用于摘要 [Yang et al., 2020b] 和对话系统 [Wolf et al., 2019]。 Zheng and Lapata [2019] 提出根据语义相似性重新排列句子顺序。 CBT [Sun et al., 2019a] 在跨模态训练中提出了噪声对比估计 (NCE),以鼓励模型与一组负面干扰项相比识别正确的视频-文本对。
Denoising autoencoding (DAE) 将损坏的文本作为输入,旨在恢复原始文本。 使用 DAE 微调的模型具有很强的理解整体句子和捕捉更远范围相关性的能力。 例如,TED [Yang et al., 2020b] 利用 DAE 来提炼抽象摘要的基本语义信息。 XGPT [Xia et al., 2020] 尝试使用图像条件denoising autoencoding (IDA) 对底层文本图像对齐进行建模,以强制模型重建整个句子。
Preserving Fidelity. 文本保真度是指生成的文本如何与原始输入信息保持一致,这是许多文本生成任务中需要考虑的重要方面。 PLM 中的通用结构无法在特定文本生成任务中保持文本保真度。 对于表格到文本的生成任务,需要对表格的结构信息进行编码。 Gong et al. [2020] 提出利用多任务学习,以便从table embeddings中重建并强制table embeddings和content embeddings之间的匹配。 此外,指针生成器 [See et al., 2017] 可以应用于 KG 到文本的生成,以复制 KG [Chen et al., 2020b] 中的实体和关系信息。
6.3 、Model View
要提高生成文本的质量,关键是要根据任务特定的数据很好地训练 PLM 的参数,以便 PLM 可以捕获专门用于生成任务的语义特征。 但是,如上所述,特定于任务的数据不足,因此在对有限数据进行fine-tuned时很可能出现过拟合情况。 在这一部分中,我们将针对模型介绍几种fine-tuning方法。
Gu et al. [2020] 采用fixed teacher GPT 来保存在另一个fine-tuned GPT 中编码的知识。 Chen et al. [2020a] 提出利用 BERT 模型(teacher)作为监督来指导 Seq2Seq 模型(student)以获得更好的生成performance。 此外,Liu 和 Lapata [2019] 利用两个优化器分别更新 PLM 和初始模块的参数,以解决两个模块之间的差异。
还存在其他指导fine-tuning过程的方法。 例如,强化学习可以通过不可微的指标直接引导模型 [Zhang et al., 2019a],例如 ROUGE。 Zhao et al. [2020] 利用课程学习让模型从简单文档学习到困难文档。 此外,DIALOGPT [Zhang et al., 2020] 实施了最大互信息 (MMI) 评分功能,以减轻产生乏味、无信息的响应。
7 、结论和未来展望
本文概述了在用于文本生成的预训练语言模型中取得的最新进展。 我们主要总结了 PLM 在对输入中的不同数据类型进行建模和在输出中满足特殊文本属性方面的扩展。 我们还讨论了几种有用的文本生成fine-tuning策略。
为了推进这一领域,将 PLM 应用于文本生成有几个有前途的未来方向。
Model Extension. 尽管在第 3 节中提出了各种扩展,但预训练和下游生成任务之间仍然存在差异。 例如,pretraining 阶段的“[MASK]”token 将不会在fine-tuning 阶段使用,这进一步加剧了 pretraining-finetuning 的差异。 因此,它进一步希望为文本生成设计一个合适的预训练范式。 此外,在预训练期间将外部知识纳入 PLM 已被证明是有效的 [Zhang et al., 2019c],并且很有希望研究如何为文本生成注入相关知识。
Controllable Generation. 使用 PLM 生成可控文本是一个有趣的方向,但仍处于非常早期的阶段。 控制生成文本的某些属性有许多有用的应用,例如在对话系统中对抑郁症患者产生积极的反应。 然而,PLM 通常在通用语料库中进行预训练,难以控制生成文本的多粒度属性(例如情感、主题和连贯性)。 Keskar et al. [2019]探索了使用控制样式、内容和特定任务行为的控制代码生成文本。 同时,这些控制代码是预设的和粗粒度的。 未来的工作可以探索多粒度控制并开发足够可控的 PLM。
Model Compression. 尽管具有大规模参数的 PLM 在文本生成方面取得了成功,但这些模型在资源受限的环境中部署具有挑战性。 因此,研究如何以少量参数实现竞争性能具有重要意义。 已经提出了几种压缩 PLM 的方法,例如参数共享 [Lan et al., 2020] 和知识蒸馏 [Sanh et al., 2019],而大多数方法都集中在基于 BERT 的模型上,很少受到关注 压缩 PLM 以生成文本。
Fine-tuning Exploration. 预训练的直接目的是将 PLM 中学到的语言知识提炼到下游生成任务中。 并且,fine-tuning是目前主要的传输方法。 可以有多种方法将知识从 PLM 转移到下游模型。 例如,Chen et al. [2020a] 通过采用 BERT 作为teacher模型和普通 RNN 生成模型作为student模型来利用知识蒸馏。 通过这种方法,可以将 BERT 的语言知识提炼到下游模型中。
Language-agnostic PLMs. 如今,几乎所有用于文本生成的 PLM 都主要基于英语。 这些 PLM 在处理非英语生成任务时会遇到挑战。 因此,与语言无关的 PLM 值得研究,它需要捕获跨不同语言的通用语言和语义特征。 一个有趣的方向是如何重用现有的基于英语的 PLM 来生成非英语语言的文本。
Ethical Concern. 目前,PLM 是在从网络上抓取的大规模语料库上进行预训练的,没有进行细粒度过滤,这可能会导致伦理问题,例如生成有关用户的私人内容。 因此,研究人员应尽最大努力防止滥用 PLM。 为此,我们可以遵循 Blank [2011] 提供的关键步骤,例如识别威胁和潜在影响以及评估可能性。 此外,PLM 生成的文本可能存在偏见,这与训练数据在性别、种族和宗教维度上的偏差一致 [Brown et al., 2020]。 因此,我们应该干预 PLM 以防止这种偏差。 对一般方法的研究是广泛的,但对于 PLM 来说仍然是初步的。
Acknowledgement
This work was partially supported by the National Key R&D Program of China under Grant No. 2020AAA0105200, National Natural Science Foundation of China under Grant No. 61872369 and 61832017, Beijing Academy of Artificial Intelligence (BAAI) under Grant No. BAAI2020ZJ0301, Beijing Outstanding Young Scientist Program under Grant No.BJJWZYJH012019100020098, the Fundamental Research Funds for the Central Universities, and the Research Funds of Renmin University of China under Grant No.18XNLG22 and 19XNQ047. Xin Zhao is the corresponding author.
References
[Bahdanau et al., 2015] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
[Bao et al., 2020] Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhen Guo, Zhibin Liu, and Xinchao Xu. PLATO-2: towards building an opendomain chatbot via curriculum learning. arXiv preprint arXiv:2006.16779, 2020.
[Blank, 2011] Rebecca M Blank. Guide for conducting risk assessments. 2011.
[Brown et al., 2020] Tom B. Brown, Benjamin Mann, and Nick Ryder et al. Language models are few-shot learners. In NeurIPS, 2020.
[Chen et al., 2020a] Yen-Chun Chen, Zhe Gan, Yu Cheng, Jingzhou Liu, and Jingjing Liu. Distilling knowledge learned in BERT for text generation. In ACL, 2020.
[Chen et al., 2020b] Zhiyu Chen, Harini Eavani, Wenhu Chen, Yinyin Liu, and William Yang Wang. Few-shot NLG with pre-trained language model. In ACL, 2020.
[Conneau and Lample, 2019] Alexis Conneau and Guillaume Lample. Cross-lingual language model pretraining. In NeurIPS, 2019.
[Devlin et al., 2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
[Dong et al., 2019] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified language model pretraining for natural language understanding and generation. In NeurIPS, 2019.
[Fan et al., 2019] Zhiyun Fan, Shiyu Zhou, and Bo Xu. Unsupervised pre-training for sequence to sequence speech recognition. CoRR, arXiv preprint arXiv:1910.12418, 2019.
[Gehring et al., 2017] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. In ICML, 2017.
[Gong et al., 2020] Heng Gong, Yawei Sun, Xiaocheng Feng, Bing Qin, Wei Bi, Xiaojiang Liu, and Ting Liu. Tablegpt: Few-shot table-to-text generation with table structure reconstruction and content matching. In COLING, 2020.
[Gu et al., 2020] Jing Gu, Qingyang Wu, Chongruo Wu, Weiyan Shi, and Zhou Yu. A tailored pre-training model for task-oriented dialog generation. arXiv preprint arXiv:2004.13835, 2020.
[Guan et al., 2020] Wang Guan, Ivan Smetannikov, and Man Tianxing. Survey on automatic text summarization and transformer models applicability. In CCRIS, 2020.
[Hendrycks et al., 2020] Dan Hendrycks, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh Krishnan, and Dawn Song. Pretrained transformers improve out-ofdistribution robustness. In ACL, 2020.
[Keskar et al., 2019] Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. CTRL: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858, 2019.
[Kryscinski et al., 2018] Wojciech Kryscinski, Romain Paulus, Caiming Xiong, and Richard Socher. Improving abstraction in text summarization. In EMNLP, 2018.
[Lan et al., 2020] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In ICLR, 2020.
[Lewis et al., 2020] Mike Lewis, Yinhan Liu, and Naman Goyal et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In ACL, 2020.
[Li et al., 2019] Junyi Li, Wayne Xin Zhao, Ji-Rong Wen, and Yang Song. Generating long and informative reviews with aspect-aware coarse-to-fine decoding. In ACL, pages 1969–1979, 2019.
[Li et al., 2020] Junyi Li, Siqing Li, Wayne Xin Zhao, Gaole He, Zhicheng Wei, Nicholas Jing Yuan, and Ji-Rong Wen. Knowledge-enhanced personalized review generation with capsule graph neural network. In CIKM, pages 735–744, 2020.
[Li et al., 2021a] Junyi Li, Tianyi Tang, Gaole He, Jinhao Jiang, Xiaoxuan Hu, Puzhao Xie, Zhipeng Chen, Zhuohao Yu, Wayne Xin Zhao, and Ji-Rong Wen. Textbox: A unified, modularized, and extensible framework for text generation. arXiv preprint arXiv:2101.02046, 2021.
[Li et al., 2021b] Junyi Li, Tianyi Tang, Wayne Xin Zhao, Zhicheng Wei, Nicholas Jing Yuan, and Ji-Rong Wen. Few-shot knowledge graph-to-text generation with pretrained language models. In Findings of ACL, 2021.
[Li et al., 2021c] Junyi Li, Wayne Xin Zhao, Zhicheng Wei, Nicholas Jing Yuan, and Ji-Rong Wen. Knowledge-based review generation by coherence enhanced text planning. In SIGIR, 2021.
[Lin et al., 2020] Zehui Lin, Xiao Pan, Mingxuan Wang, Xipeng Qiu, Jiangtao Feng, Hao Zhou, and Lei Li. Pretraining multilingual neural machine translation by leveraging alignment information. In EMNLP, 2020.
[Liu and Lapata, 2019] Yang Liu and Mirella Lapata. Text summarization with pretrained encoders. In EMNLP, 2019.
[Mager et al., 2020] Manuel Mager, Ram ´on Fernandez Astudillo, Tahira Naseem, Md. Arafat Sultan, Young-SukLee, Radu Florian, and Salim Roukos. Gpt-too: A language-model-first approach for amr-to-text generation. In ACL, 2020.
[Peters et al., 2018] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In NAACL-HLT, 2018.
[Qiu et al., 2020] Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. Pre-trained models for natural language processing: A survey. arXiv preprint arXiv:2003.08271, 2020.
[Radford et al., 2019] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
[Raffel et al., 2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020.
[Ribeiro et al., 2020] Leonardo F. R. Ribeiro, Martin Schmitt, Hinrich Sch ¨utze, and Iryna Gurevych. Investigating pretrained language models for graph-to-text generation. arXiv preprint arXiv:2007.08426, 2020.
[Rothe et al., 2020] Sascha Rothe, Shashi Narayan, and Aliaksei Severyn. Leveraging pre-trained checkpoints for sequence generation tasks. TACL, 2020.
[Sanh et al., 2019] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
[See et al., 2017] Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer-generator networks. In ACL, 2017.
[Song et al., 2019] Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MASS: masked sequence to sequence pre-training for language generation. In ICML, 2019.
[Sun et al., 2019a] Chen Sun, Fabien Baradel, Kevin Murphy, and Cordelia Schmid. Contrastive bidirectional transformer for temporal representation learning. arXiv preprint arXiv:1906.05743, 2019.
[Sun et al., 2019b] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. In ICCV, 2019.
[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
[Wada and Iwata, 2018] Takashi Wada and Tomoharu Iwata. Unsupervised cross-lingual word embedding by multilingual neural language models. arXiv preprint arXiv:1809.02306, 2018.
[Wolf et al., 2019] Thomas Wolf, Victor Sanh, Julien Chaumond, and Clement Delangue. Transfertransfo: A transfer learning approach for neural network based conversational agents. arXiv preprint arXiv:1901.08149, 2019.
[Xia et al., 2020] Qiaolin Xia, Haoyang Huang, Nan Duan, Dongdong Zhang, Lei Ji, Zhifang Sui, Edward Cui, Taroon Bharti, Xin Liu, and Ming Zhou. XGPT: cross-modal generative pre-training for image captioning. arXiv preprint arXiv:2003.01473, 2020.
[Xu et al., 2020a] Jiacheng Xu, Zhe Gan, Yu Cheng, and Jingjing Liu. Discourse-aware neural extractive text summarization. In ACL, 2020.
[Xu et al., 2020b] Shusheng Xu, Xingxing Zhang, Yi Wu, Furu Wei, and Ming Zhou. Unsupervised extractive summarization by pre-training hierarchical transformers. In EMNLP, 2020.
[Yang et al., 2020a] Zhen Yang, Bojie Hu, Ambyera Han, Shen Huang, and Qi Ju. CSP: code-switching pre-training for neural machine translation. In EMNLP, 2020.
[Yang et al., 2020b] Ziyi Yang, Chenguang Zhu, Robert Gmyr, Michael Zeng, Xuedong Huang, and Eric Darve. TED: A pretrained unsupervised summarization model with theme modeling and denoising. In EMNLP (Findings), 2020.
[Zaib et al., 2020] Munazza Zaib, Quan Z. Sheng, and Wei Emma Zhang. A short survey of pre-trained language models for conversational AI-A new age in NLP. In ACSW, 2020.
[Zeng and Nie, 2020] Yan Zeng and Jian-Yun Nie. Generalized conditioned dialogue generation based on pre-trained language model. arXiv preprint arXiv:2010.11140, 2020.
[Zhang et al., 2019a] Haoyu Zhang, Jingjing Cai, Jianjun Xu, and Ji Wang. Pretraining-based natural language generation for text summarization. In CoNLL, 2019.
[Zhang et al., 2019b] Xingxing Zhang, Furu Wei, and Ming Zhou. HIBERT: document level pre-training of hierarchical bidirectional transformers for document summarization. In ACL, 2019.
[Zhang et al., 2019c] Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. ERNIE: enhanced language representation with informative entities. In ACL, 2019.
[Zhang et al., 2020] Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. DIALOGPT : Largescale generative pre-training for conversational response generation. In ACL, 2020.
[Zhao et al., 2020] Xueliang Zhao, Wei Wu, Can Xu, Chongyang Tao, Dongyan Zhao, and Rui Yan. Knowledge-grounded dialogue generation with pretrained language models. In EMNLP, 2020.
[Zheng and Lapata, 2019] Hao Zheng and Mirella Lapata. Sentence centrality revisited for unsupervised summarization. In ACL, 2019.
[Zhou et al., 2020] Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J. Corso, and Jianfeng Gao. Unified vision-language pre-training for image captioning and VQA. In AAAI, 2020.